研究内容

意味論的領域分割に基づく自律走行

ビジュアルナビゲーションを対象とした実環境における意味論的領域分割の精度向上

三次元点群モデルを用いた
データセット自動生成

意味論的領域分割の高速化
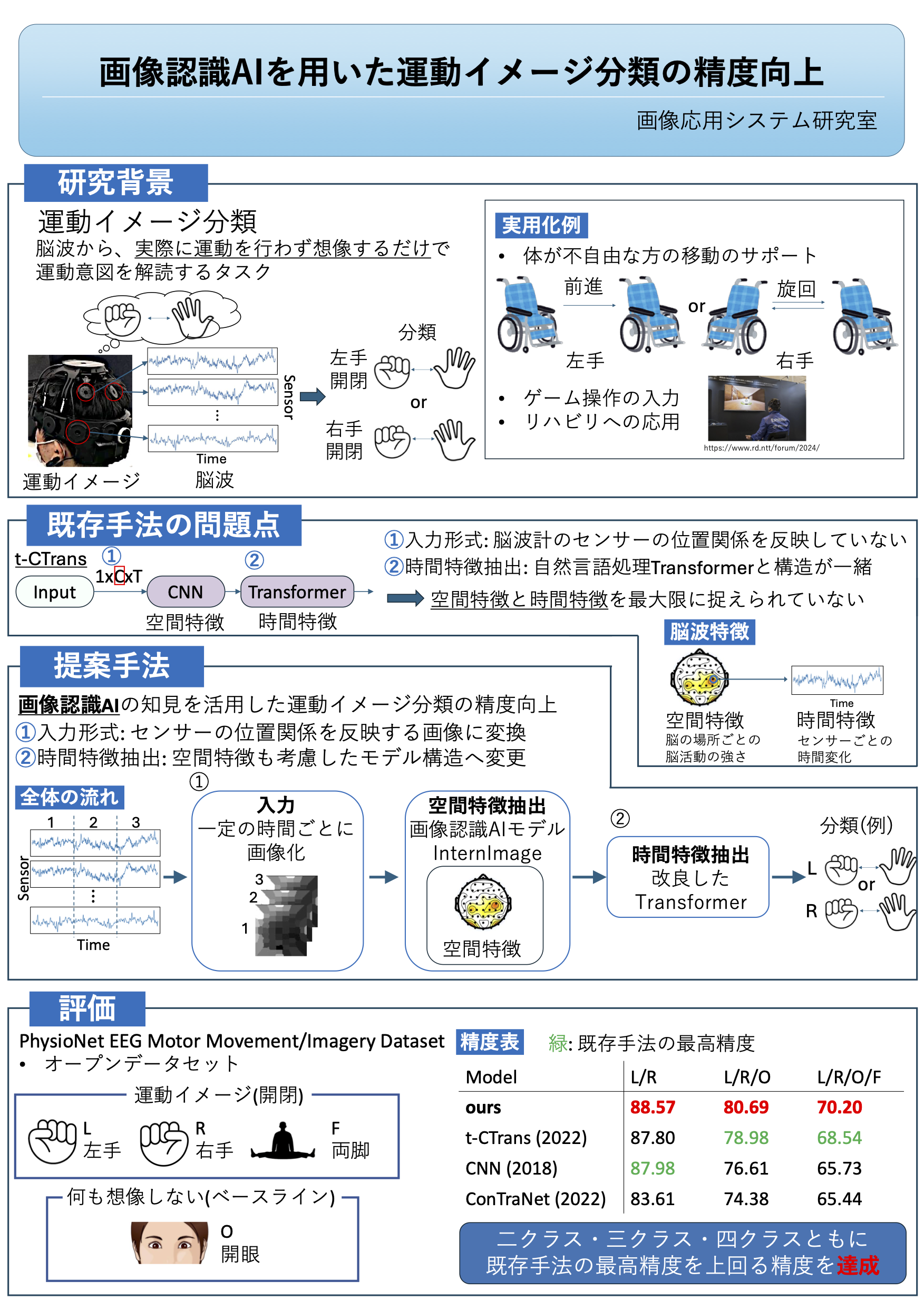
画像認識AIを用いた
運動イメージ分類の精度向上
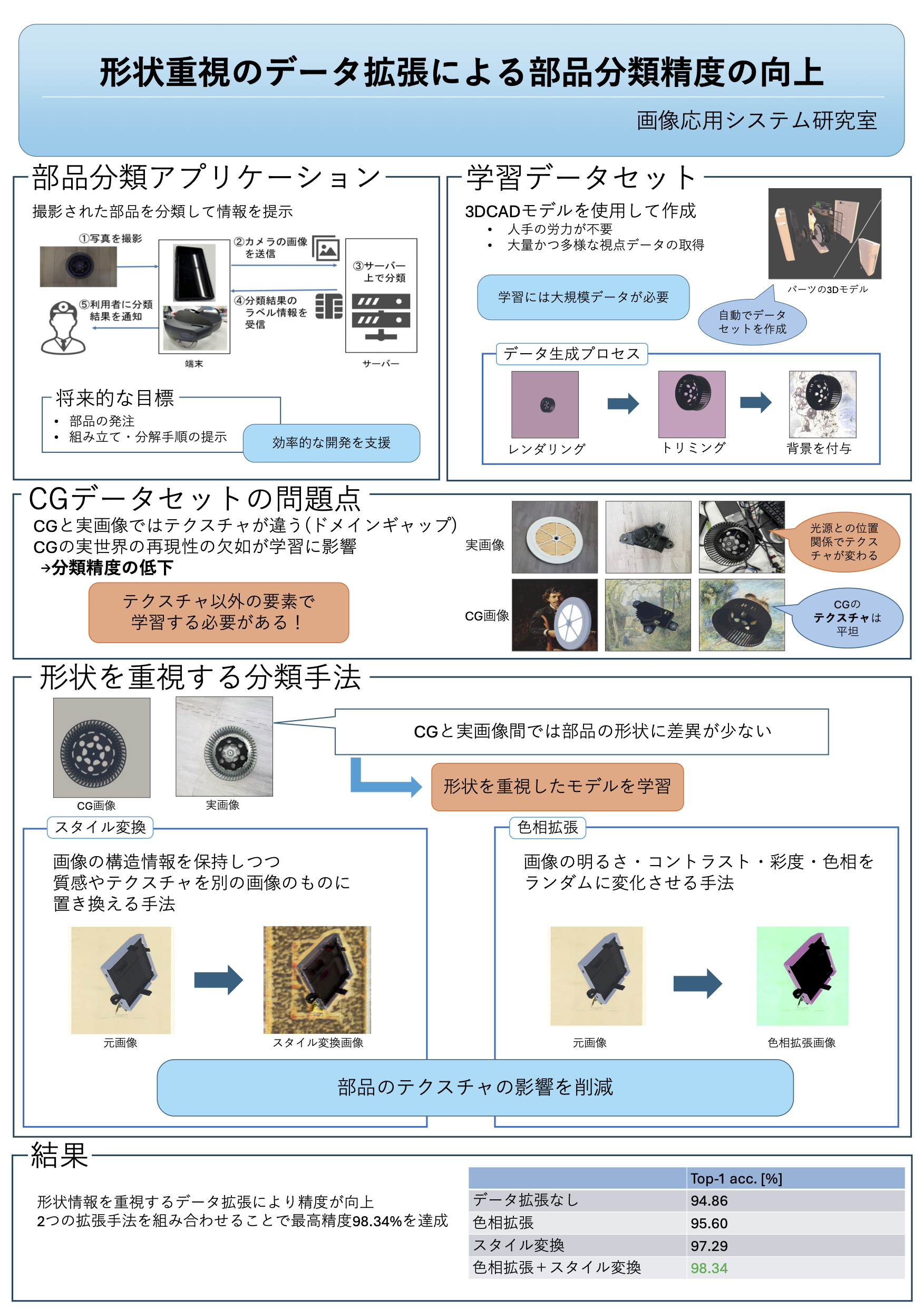
形状重視のデータ拡張による
部品分類精度の向上

バーチャル内見のための部屋の3次元構造推定
その他の研究は,業績を参考にしてください
過去の研究テーマの例
パターン認識系
-
Channel Feature 系の手法を応用した物体検出
-
画像ボケを手掛かりとした物体検出
-
関節の動きに着目した歩容解析
-
キャラクターの顔画像からの特徴点抽出
-
ゲーム AI の構築
AlphaGo が世界トップクラスの棋士と5番勝負を行い4勝したことは記憶に新しいところですが、特に驚くべきことは、囲碁における戦略を自己対戦の結果に基づく強化学習によって獲得したという点にあります。将棋も含めて、ターン性のゲームについては先行研究が進んでいますが、我々はターン性ではない格闘ゲームを対象とし、最適戦略を自己対戦を中心とした強化学習によって獲得することを目指した研究に取り組んでいます。このような動的な環境を対象とした強化学習に関する研究は、ゲームだけではなく、スポーツや格闘技の戦略分析、さらには現実の社会活動における最適戦略の構築にも繋がると考えています。

-
情景内文字検出・認識
-
アニメや漫画のキャラクターを対象とした2次元画像からの3次元モデル構築
-
視線検出のための瞳孔抽出
-
Deep Learning の応用
巷では Deep Learing (深層学習) が大流行ですが、人検出においては Channel Feature 系の手法が圧倒的な精度を示しており、現状では全く勝負になっていません。我々は、Deep Learning を代表としたこの分野の流行をしっかりと追い掛けつつも、既存手法にまだまだ性能向上の余地があると判断し、Channel Feature 系の手法をさらに利用し易くすべく、精度向上と計算量削減の両立やマルチクラス識別器への拡張等に取り組んでいます。
物体検出は車やロボットの自律移動、不審人物や違法操業漁船の検知等に不可欠な技術ですが、通常の自然画像のみを用いて所望の物体を検出することは非常に困難なタスクです。我々は、芸術的な写真で利用されている特定の対象にのみピントを合わせて、他の領域をボケさせるという技法に着想を得て、敢えて被写界深度の浅いカメラを用いることにより高精度に物体検出を行えるのではないかと考えました。実際、Haar-like 特徴と離散フーリエ変換を組み合わせただけでも結果は極めて良好で、特定の領域に存在する物体の検出というタスクを解くのには非常に有効な手法であると言えます。合成画像を使った実験では、DET 曲線が横軸と一致する、つまり完全な分離を実現できています。この手法は広く実アプリケーションに利用できると期待して、特許出願中です!!

人の歩き方のことを歩容と言い、歩容からは様々な情報を得ることができます。近年では、性別や年齢に加えて、個人識別も可能となっており、消費行動解析や安全・安心な社会の実現に大きく貢献することが期待されています。既存研究では人の手足の動く速度に着目した手法が主流だったのですが、我々は関節の動きそのものに着目することで個人情報の推定が可能であると考え、研究に取り組んでおります。Kinect を用いて関節座標を取得することによって、現在は 90% 以上の個人認識精度を達成しております。今後は、画像のみによる処理の実現を行うことにより、スポーツ選手のフォーム解析や疲労度の推定、安全・安心な社会の実現を目指したインテリジェントサーベイランスシステムの構築といった新たな応用を計画中で、まだまだ成果が挙がりそうな研究テーマです。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
顔画像からの特徴点抽出は個人識別や表情認識等に有効であるため様々な手法が提案されており、特に、機械学習を積極的に用いる手法は顕著な成果を挙げています。しかし、既存の研究は自然画像を対象としたものばかりであり、アニメや漫画のキャラクターのようなベタ塗りを多く含む顔画像を対象とした研究は存在しません。我々は、キャラクターの識別やシーン解析だけでなく、下に示すようなキャラクターの2次元画像からの3次元構造の構築への応用も視野に入れ、高精 度な特徴点抽出手法の実現を目指しています。以下に示す画像は現在の手法による検出例です。
 |
 |
 |
 |

|

|
印刷された文書に対する文字認識はほぼ完成された技術であり、実用的な精度が実現できています。しかし、一般的なシーンから文字を見付け、そこに何が書かれているかを判断することは、コンピュータには困難な課題であり、まだまだ精度向上の余地が残されています。我々はこの課題に対して物体検出で培った知見を応用するという立場から取り組んでいます。

|

|

|

|

|

|

|

|
通常の画像は平面に射影された情報しか有していないため、実空間における3次元情報を失っています。この失われた情報を復元するための研究は盛んに行われており、自然画像を対象とした研究では1枚の画像から3次元情報をある程度復元することも可能となっています。このような3次元情報の復元を3次元再構成と言いますが、顔画像を入力として人の頭部の3次元情報を復元しようとする研究は盛んに研究されている分野の1つです。頭部の3次元再構成のうち、自然画像を入力とした研究はある程度の性能が達成されていますが、アニメや漫画のようなイラストを入力としてキャラクターの3次元モデルを構築することは困難な課題であるため、実用的な精度は達成されていません。その理由は、そもそもキャラクターのイラストは3次元情報から生成されたものではないこと、ベタ塗りが多く複数の画像からの特徴点の対応付けが困難であること等が挙げられます。我々はこの課題に対して、事前に用意したモデルをイラストに合わせて変形することにより、違和感の少ない3次元モデルを構築することを目指しています。
仮想現実の提示デバイスの1つとしてヘッドマウントディスプレイ (HMD) が発売されていますが、HMD を装着した場合に簡便にコンピュータにコマンドを送る方法は未だ確立されていません。我々は、視線を用いてコンピュータにコマンドを送るインターフェースの実現を目指しており、それに必要な視線検出方式を提案しています。現在は、赤外光を光源として用意した場合の動作検証しか行えていませんが、視線の検出はコンピュータとのインターフェース以外にも様々な応用が考えられるため、可視光下での動作を目指した研究に取り組んでいます。
人検出においては最高精度に程遠い性能しか示せていないものの、Deep Learning にも利点はあると我々は考えております。それは、まだ研究が進んでおらず、どのような方向から攻めるべきかの見当すらついていない課題に対してもそれなりの精度を達成できるということです。我々は Deep Learning による学習結果を新たな手法を構築するためのヒントとして適切に利用することを目的として、様々な課題への Deep Learning の応用に取り組んでいます。
システム実装系
-
セマンティックセグメンテーションを用いたロボットの自律走行
-
物体検出システムの FPGA 実装
-
USB カメラからハードウェア IP への画像転送システムの構築
-
Stixel world の zynq を用いた実装
-
知的なロボット制御
-
ロボットの自律移動

AR・VR 系
-
Virtual Boxing
-
ドラム演奏技術獲得のためのトレーニング支援システム
-
仮想粘土

|

|

|
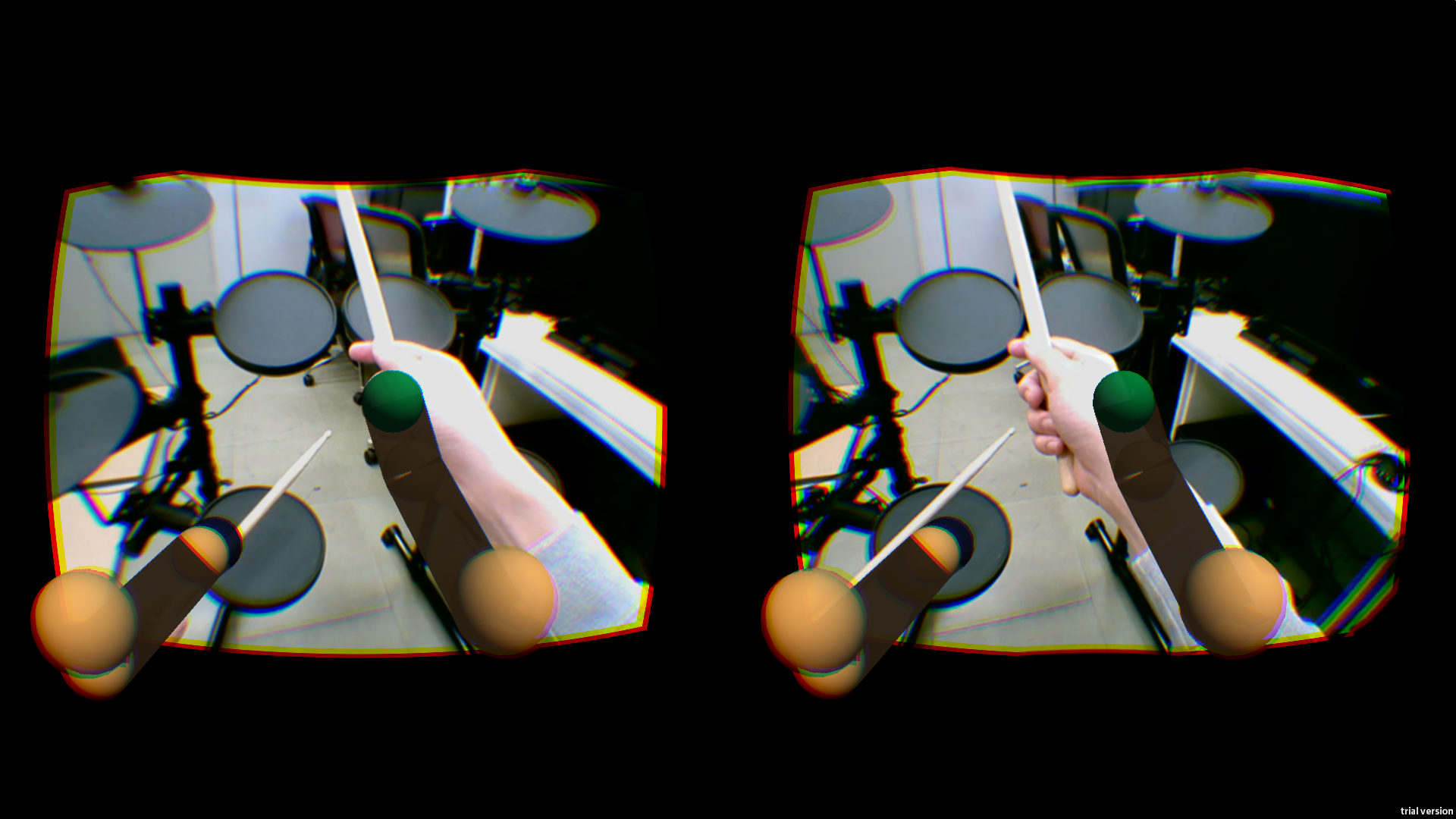
|
仮想空間内での3次元モデリングの実現を目指して、仮想粘土の構築を行っています。
錯視・錯覚の応用
未発表のためまだ公開できませんが錯視や錯覚を用いた臨場感の向上の実現を目指しています。
その他
-
画像符号化
モバイル端末での再生に適した画像符号化および復号方式について研究しています。動画配信を行っている会社との共同研究です。